Spider…
HTTP 状态码测试网址:http://httpstat.us/
作者代码地址:https://bitbucket.org/wswp/
Book’Name:《Web Scraping with Python》
- Introduce
- Crawl Data 2.1 RegEx&Beautiful Soup&lxml
- Cache Download 3.1 DiskCache&MongoDB
- Multi Process&Threading
- Dynamic Content 5.1 Reverse 5.2 Dynamic rendering 5.2.1 PyQt&PySide 5.2.2 Selenium
- Form 6.1 Aificial&Mechanize
- Captcha
- Scrapy 8.1 Portia
- Summary
1
urllib2.URLError
可以获取返回的状态码urllib2.URLError.code
用户代理
默认情况下使用Python-urllib/2.7
css选择器-sitemap
使用正则
def crawl_sitemap(url):
sitemap = download(url)
links = re.findall('<loc>(.*?)</loc>', sitemap)
for link in links:
html = download(link)
itertools
可以用来创建无限迭代器.itertools.count(1)表示自然数序列
urlparse
urlparse.urlparse()
>>> urlparse.urlparse('https://www.baidu.com')
ParseResult(scheme='https', netloc='www.baidu.com', path='', params='', query='', fragment='')
urlparse.urljoin()
>>> urlparse.urljoin('https://www.baidu.com','index.php')
'https://www.baidu.com/index.php'
>>> urlparse.urljoin('https://www.baidu.com/123','index.php')
'https://www.baidu.com/index.php'
>>> urlparse.urljoin('https://www.baidu.com/123','/index.php')
'https://www.baidu.com/index.php'
>>> urlparse.urljoin('https://www.baidu.com/123/','index.php')
'https://www.baidu.com/123/index.php'
>>> urlparse.urljoin('https://www.baidu.com/123/','/index.php')
'https://www.baidu.com/index.php'
注:如果第一个参数有目录的话,记得添加最后的/,并且添加之后不需要第二个参数添加
robotparse
用于判定是否用户代理允许访问页面
def get_robot(user_agent, url):
rp = robotparser.RobotFileParser()
rp.set_url(urlparse.urljoin(url, '/robots.txt'))
rp.read()
rp.can_fetch(user_agent, url) //返回ture/false
Proxy
使用urllib2支持代理
request = urllib2.Request(url,...)
opener = urllib2.build_opener()
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
response = opener.open(request)
set
>>> a=set('http://example.webscraping.com/')
>>> print a
set(['a', 'o', 'c', 'b', 'e', 'g', 'n', 'i', 'h', 'm', 'l', '/', '.', 'p', 's', 'r', 't', 'w', 'x', ':'])
>>> a.add('/index/1')
>>> print a
set(['a', 'o', 'c', 'b', 'e', 'g', 'n', 'i', 'h', '/index/1', 'm', 'l', '/', '.', 'p', 's', 'r', 't', 'w', 'x', ':'])
2
Firebug中的html是被js渲染过后的代码,所以与源代码不完全相同
BeautifulSoup
soup = BeautifulSoup(html) # 把下载下来的html进行格式化
find('li',attrs{'id':'id_value'})、find_all() # 寻找标签,同时可以指定元素
Lxml
解析速度要快于BeautifulSoup
XPath和CSS选择器
tree = lxml.html.fromstring(html)
result = tree.cssselect('table > tr#places_area__row > td.w2p_fw')[0].text_content() #cssselect需要下载
a > b : 选择父标签为a的b子标签
a#b : 选择class='b'的a标签
a.b : 选择id='b'的a标签
性能:Lxml/Regex>Beautiful,Lxml是最好的选择
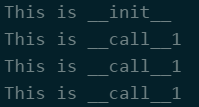
call
class Test:
def __init__(self):
print "This is __init__"
def __call__(self, pra):
print "This is __call__{}".format(pra)
def func_test(class_name=None):
for i in range(3):
class_name(1)
if __name__ == '__main__':
func_test(class_name=Test())
Result:
| 抓取方法 | 性能 | 难度 |
|---|---|---|
| RegEx | 快 | 难 |
| Beautiful Soup | 慢 | 易 |
| lxml | 快 | 易 |
3&4
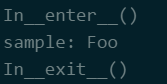
with … as …
with求值的对象必须有一个__enter__()方法,一个__exit()__方法 处理顺序:对象被求值后,返回对象的__enter__方法被调用,返回值被赋值给as后面的变量,with后面的代码块全部执行玩之后,调用对象的返回的__exit__方法
class Sample:
def __enter__(self):
print "In__enter__()"
return "Foo"
def __exit__(self, type, value, trace):
print "In__exit__()"
def get_sample():
return Sample()
with get_sample() as sample:
print "sample:", sample
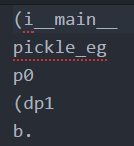
pickle模块
实现了基本的数据序列化和反序列化.序列化之后的对象保存到文件中,从文件中反序列化对象的信息.
pickle.dump(obj,file[,protocol]) //protocol表示序列化模式
pickle.load(file)
Eg:2017-06-16 11:25:25 星期五:
import pickle
class pickle_eg:
def __init__(self):
pass
pickle_eg1 = pickle_eg()
f = open('pickle_eg.txt','wb')
pickle.dump(pickle_eg1,f)
f.close()
f = open('pickle_eg.txt','r')
data = pickle.load(f)
f.close()
print data
写入文件和导出的结果:

getitem&setitem
class setandget:
k={}
def __getitem__(self,key):
return self.k[key]
def __setitem__(self,key,value):
self.k[key] = value
a = setandget()
a['test'] = 1
print a['test']
a.__setitem__('test2',2)
print a.__getitem__('test2')
print a['test2']

5
注:Python解析js动态网站:js逆向、渲染js
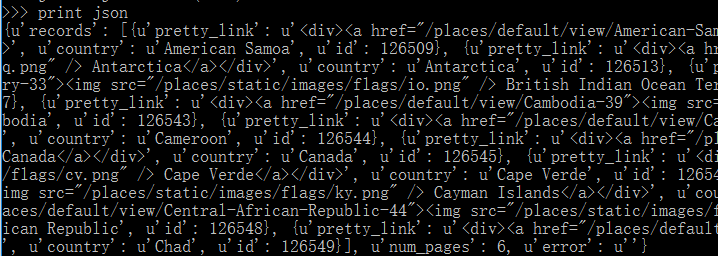
Json
Ajax响应返回的数据是Json格式的,使用Json模块解析为一个字典
import json,urllib2
url = 'http://example.webscraping.com/places/ajax/search.json?&search_term=c&page_size=10&page=0'
html = urllib2.urlopen(url).read()
json = json.loads(html)
print json
PyQt&PySide
Qt框架下的两个python库,通过Qt框架的库来获得WebKit渲染引擎的python接口
url = 'http://example.webscraping.com/places/default/search'
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
webview.loadFinished.connect(loop.quit)
webview.load(url)
loop.exec_()
webview.show()
html = webview.page().mainFrame()
- QApplication对象需要在其他Qt对象完成初始化之前完成创建
- QWebView对象是Web文档的容器
- QEventLoop对象用于创建本地事件循环
- QWebView对象的loadFinished回调连接了QEventLoop的quit方法,从而可以在网页加载完成之后停止事件循环
- QWebView加载URL(PyQt需要把URL封装在QUrl对象中)
- 由于QWebView加载方法是异步的,因为需要等待网页加载完成,所以调用loop.exec_()
- 调用QWebView的show方法来显示渲染窗口
- webview.page().mainFrame()返回框架
- app.processEvents()用于给Qt事件循环执行任务的时间
Selenium
Chrome缺少驱动需要自行下载再设置为环境变量chromdriver Firefox 47以上版本下载第三方驱动,geckodriver
6
POST表单
e_data = urllib.urlencode(data)
request = urllib2.Request(url, data)
response = urllib2.urlopen(request)
urlopen使用默认的opener的对象中的open方法 opener可以自定义,通过urllib2.build_opener方法,之后使用opener的open方法打开urllib2.Request
添加cookie
Cookielib
CookieJar/MozillaCookieJar/FileCookieJar/LWPCookieJar
cookie = Cookielib.CookieJar() //创建放置Cookie的容器
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) //自定义opener,使其支持cookie
response = opener.open(urllib2.Request())
build_opener生成一个自定义的opener
获取session文件路径
Windows:
%APPDATA%\Mozilla\Firefox\Profiles\*.default\sessionstore-backups
**注:
1.书中说的文件是根目录下的sessionstore.js,如果没有这个文件使用sessionsor-backups下的recovery.js代替即可
2.目录不一定符合这个*.default
**
Mechanize
可以直接生成表单,并且不需要进行cookie管理
import mechanize
me = mechanize.Browser()
me.open(url)
me.select_form(nr=0) // 选择第一个表单
br.form //显示目前表单的状态
br['key'] = value
br.submit() //提交表单
7
Pillow&Tesseract-OCR
pillow的使用需要借助Tessract-OCR
import pytesseract
from PIL import Image
img = Image.open('captcha.png')
gray = img.convert('L')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
tessdata_dir_config = '--tessdata-dir "C:\\Program Files\\Tesseract-OCR\\tessdata"'
print pytesseract.image_to_string(bw, config=tessdata_dir_config)
注:在Win10下安装Tesseravt-OCR之后,tesserdata路径出错,由于驱动器的原因,所以使用的时候需要手动设置tesserdata的路径
(ง •_•)ง